Contribution Guide
Welcome to the Qbeast community! Nice to meet you :)
Here's a summary of what you can find in this page:
- Introduction
- Version control branching
- PRs and Issues
- Style and formatting
- Logging Documentation
- Developing and contributing
- Publishing Guide
- Versioning
- Licensing of contributed material
- Community Values
Introduction
Either you want to know more about our guidelines or open a Pull Request, this is your page. We are pleased to help you through the different steps for contributing to our (your) project.
To find Qbeast issues that make good entry points:
-
Start with issues labelled
. For example, see the good first issues in the repository for updates to the core Qbeast Spark code.
-
For issues that require deeper knowledge of one or more technical aspects, look at issues labelled
.
Version control branching
- Always make a new branch for your work, no matter how small
- Don´t submit unrelated changes to the same branch/pull request
- Base your new branch off of the appropriate branch on the main repository
- New features should branch off of the
mainbranch
PRs and Issues
To open and merge PRs, the following is to be respected:
- Always open an issue for the PR you're working with as much detail as possible.
- Every PR should have an issue that it is trying to address, ideally one.
- The title of the PR should follow the schema: Issue <issue-number>: <PR-title>
- Ideally, there should be at least two reviewers per PR
- The author of the PR never gets to merge the PR; a PR can only be merged by a reviewer.
- Do a Squash and Merge instead of merge, again, by a reviewer.
- Make sure the commit messages in the Squash Merge are clear and concise and reflect all major changes introduced by the PR.
Style and formatting
-
We follow Scalastyle for coding style in Scala. It runs at compile time, but you can check it manually with:
sbt scalastyle -
Scalafmt is used for code formatting. You can configure your IDE to reformat at save:
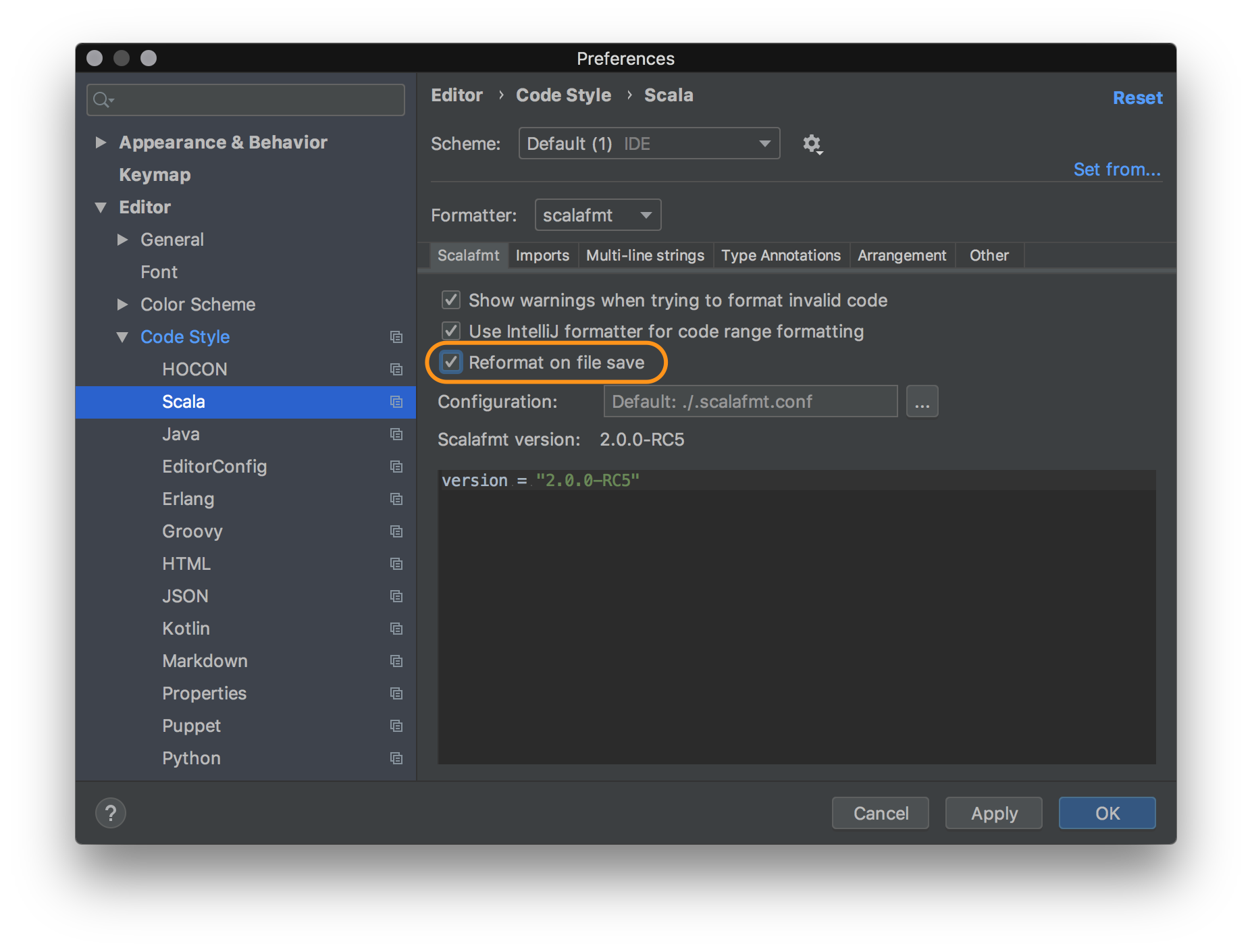
Or alternatively force code formatting:
sbt scalafmt # Format main sources
sbt test:scalafmt # Format test sources
sbt scalafmtCheck # Check if the scala sources under the project have been formatted
sbt scalafmtSbt # Format *.sbt and project/*.scala files
sbt scalafmtSbtCheck # Check if the files have been formatted by scalafmtSbt -
Sbt also checks the format of the Scala docs when publishing the artifacts. The following command will check and generate the Scaladocs:
sbt doc
Logging Documentation
- We use the Spark Logging interface.
- Spark uses
log4jfor logging. You can configure it by adding alog4j2.propertiesfile in the conf directory. One way to start is to copy the existinglog4j2.properties.templatelocated there.
An example of using logging on a class is:
import org.apache.spark.internal.Logging
case class MyClass() extends Logging \{
def myMethod(): Unit = \{
logInfo("This is an info message")
logWarn("This is a warning message")
logError("This is an error message")
logTrace("This is a trace message")
logDebug("This is a debug message")
\}
\}
The following log levels are used to track code behaviour:
-
WARNlevel is supposed to be critical and actionable. If the user sees a WARN, then something bad happened and it might require user intervention.Example on
DeltaMetadataWriterclass:def writeWithTransaction(writer: => (TableChanges, Seq[FileAction])): Unit = \{
// [...] Code to write the transaction [...]
if (txn.appId == appId && version <= txn.version) \{
val message = s"Transaction $version from application $appId is already completed," +
" the requested write is ignored"
logWarn(message)
return
\}
\} -
INFOlevel provides information about the execution, but not necessarily actionable and it avoids being verbose. It is not uncommon to see INFO level on in production, so it is expected to be lightweight with respect to the volume of messages generated.Example on
BlockWriterclass:def writeRow(rows: Iterator[InternalRow]): Iterator[(AddFile, TaskStats)] = \{
// [...] Code to write the rows [...]
logInfo(s"Adding file $\{file.path\}")
\} -
DEBUGprovides debug level info when debugging the code. It can be verbose as it is not expected to be on in production.Example on
IndexedTableclass:if (isNewRevision(options)) \{
// Merging revisions code
logDebug(
s"Merging transformations for table $tableID with cubeSize=$newRevisionCubeSize")
// Code to merge revisions
\} -
TRACEprovides further detail to DEBUG on execution paths, and in particular, it indicates the execution of critical methods.Example on
IndexedTableclass:def doWrite(
data: DataFrame,
indexStatus: IndexStatus,
options: QbeastOptions,
append: Boolean): Unit = \{
logTrace(s"Begin: Writing data to table $tableID")
// [...] Code to write the data [...]
logTrace(s"End: Writing data to table $tableID")
\}
We should enforce all the Pull Request, specially those containing critical code, to have logging messages that are meaningful and informative.
Developing and contributing
Development set up
1. Install sbt(>=1.4.7).
2. Install Spark
Download Spark 3.3.0 with Hadoop 3.3*, unzip it, and create the SPARK_HOME environment variable:
*: You can use Hadoop 2.7 or 3.2 if desired, but you could have some troubles with different cloud providers' storage, read more about it here.
wget https://archive.apache.org/dist/spark/spark-3.5.0/spark-3.5.0-bin-hadoop3.tgz
tar -xzvf spark-3.5.0-bin-hadoop3.tgz
export SPARK_HOME=$PWD/spark-3.5.0-bin-hadoop3
3. Project packaging:
Navigate to the repository folder and package the project using sbt. JDK 8 is recommended.
ℹ️ Note: You can specify custom Spark or Hadoop versions when packaging by using
-Dspark.version=3.5.0or-Dhadoop.version=2.7.4when runningsbt assembly. If you have troubles with the versions you use, don't hesitate to ask the community in GitHub discussions.
cd qbeast-spark
sbt assembly
This code generates a fat jar with all required dependencies (or most of them) shaded.
The jar does not include scala nor spark nor delta, and it is supposed to be used inside spark.
For example:
-
Delta:
sbt assembly
$SPARK_HOME/bin/spark-shell \
--jars ./target/scala-2.12/qbeast-spark-assembly-0.8.0-SNAPSHOT.jar \
--packages io.delta:delta-spark_2.12:3.1.0 \
--conf spark.sql.extensions=io.qbeast.sql.DeltaQbeastSparkSessionExtension \
--conf spark.sql.catalog.spark_catalog=io.qbeast.catalog.DeltaQbeastCatalog -
Hudi:
sbt assembly
$SPARK_HOME/bin/spark-shell \
--jars ./target/scala-2.12/qbeast-spark-assembly-0.8.0-SNAPSHOT.jar \
--packages org.apache.hudi:hudi-spark3.2-bundle_2.12:1.0.0 \
--conf spark.serializer=org.apache.spark.serializer.KryoSerializer \
--conf spark.kryo.registrator=org.apache.spark.HoodieSparkKryoRegistrar \
--conf spark.sql.extensions=io.qbeast.sql.HudiQbeastSparkSessionExtension \
--conf spark.sql.catalog.spark_catalog=io.qbeast.catalog.HudiQbeastCatalog
4. Publishing artefacts in the local repository
Sometimes it is convenient to have custom versions of the library to be
published in the local repository like IVy or Maven. For local Ivy (~/.ivy2)
use
sbt publishLocal
For local Maven (~/.m2) use
sbt publishM2
Developer documentation
You can find the developer documentation (Scala docs) in the https://docs.qbeast.io/.
Steps to contribute
1 - Click Fork on Github, and name it as yourname/projectname�
2 - Clone the project: git clone git@github.com:yourname/projectname
3 - Create a branch: git checkout -b your-branch-name
4 - Open the project with your IDE, and install extensions for Scala and sbt
5 - Make your changes
6 - Write, run, and pass tests:
Note: You can run tests for different Spark and Hadoop versions specifying them with
-Dspark.versionand-Dhadoop.version. Find an example in the Setting Up section of README.md
-
For all tests:
sbt test -
To run a particular test only:
sbt "testOnly io.qbeast.spark.index.writer.BlockWriterTest"
7 - Commit your changes: git commit -m "mychanges"
8 - Push your commit to get it back up to your fork: git push origin HEAD
9 - Go to Github and open a  against the
against the main branch of qbeast-spark.
Identify the committers and contributors who have worked on the code being changed, and ask for their review 👍
10 - Wait for the maintainers to get back to you as soon as they can!
Publishing Guide
To publish a new version of the qbeast-spark-private project, follow these steps:
ℹ️ Note: This example is for a new version 0.6.0. The same steps can be applied to any new version.
-
Update the default version in the
build.sbtfile aftergetOrElse:mainVersion := sys.props.get("MAIN_VERSION").getOrElse("0.6.0-SNAPSHOT") -
Check that all tests passed.
sbt test -
Package the code with
sbt packageand run the code in theREADMEfor a quick test on spark-shell.sbt package -
Publish a
SNAPSHOTusing the Build and publish Qbeast JARs snapshot from a branch workflow. Select the branch you want to build in the input field. The latest commit short SHA will be added automatically to the package name. For example, if mainVersion is set to0.9.0-SNAPSHOTinbuild.sbt, it will be replaced by0.9.0-SNAPSHOT-0abcdef. -
Try the same
READMEcode downloading theSNAPSHOTwith--packagesand--repositoriesconfiguration. If necessary, test it in different Cloud Provider environments.
- Delta lake:
export QBEAST_SPARK_VERSION=0.8.0-SNAPSHOT
$SPARK_HOME/bin/spark-shell --repositories https://maven.pkg.github.com/qbeast-io/qbeast-spark-private \
--packages io.delta:delta-spark_2.12:3.1.0,io.qbeast:qbeast-spark_2.12:$QBEAST_SPARK_VERSION \
--conf spark.sql.extensions=io.qbeast.sql.DeltaQbeastSparkSessionExtension \
--conf spark.sql.catalog.spark_catalog=io.qbeast.catalog.DeltaQbeastCatalog - Hudi:
export QBEAST_SPARK_VERSION=0.8.0-SNAPSHOT
$SPARK_HOME/bin/spark-shell --repositories https://maven.pkg.github.com/qbeast-io/qbeast-spark-private \
--packages org.apache.hudi:hudi-spark3.2-bundle_2.12:1.0.0,io.qbeast:qbeast-spark_2.12:$QBEAST_SPARK_VERSION \
--conf spark.serializer=org.apache.spark.serializer.KryoSerializer \
--conf spark.kryo.registrator=org.apache.spark.HoodieSparkKryoRegistrar \
--conf spark.sql.extensions=io.qbeast.sql.HudiQbeastSparkSessionExtension \
--conf spark.sql.catalog.spark_catalog=io.qbeast.catalog.HudiQbeastCatalog
- If everything is ok, you can publish the RC by tagging the git repository
git tag -a v0.6.0-rc1 -m "Release Candidate 1"
git push origin v0.6.0-rc1
The Release CI workflow will be started automatically, change the package version in build.sbt and publish the jars.
-
Set up the RC for approval. Make sure all users that had tested the version in their dev environments didn't experience any bug or performance drawback.
-
If the RC is approved, go to step 1, and publish the final version by tagging again with
v0.6.0
Here are some rules on versioning the qbeast-spark project that must be applied before a new version is released.
post 0.6.0 release
If the current version is 0.y.z, these rules must be applied for a new release:
- 0.y.z+1 for a bugfix only release
- 0.z+1.0 for a new feature(s) release
- 0.y.z-rcN for release candidates, N being a positive integer
post 1.0.0 release
We'll apply Semantic Versioning rules as defined at semver.org.
Snapshots
Snapshots can be made available for internal and test purposes.
In this case the versioning to be applied is: <new-version-number>-<short-commit-sha>-SNAPSHOT
Example: 0.6.2-badfbadf-SNAPSHOT
Licensing of contributed material
All contributed code, docs, and other materials are considered licensed under the same terms as the rest of the project. Check LICENSE for more details.
Community Values
The following are the refined values that our community has developed in order to promote continuous improvement of our projects and peers.
Make your life easier
Automate. Large projects are hard work. We value time spent automating repetitive work. Where that work cannot be automated, it is our culture to recognize and reward all types of contributions.
We're all in this together
Innovation requires alternate points of view and ranges of abilities which must be heard in an inviting and respectful environment. Community leadership is acquired through hard work, quality, quantity and commitment. Our community recognizes the time and effort put into a discussion, no matter where a contributor is on their growth journey.
Always Evolve
Qbeast Spark is a stronger project because it is open to fresh ideas. The Qbeast project culture is built on the principles of constant improvement, servant leadership, mentorship, and respect. Leaders in the Qbeast community are responsible for finding, sponsoring, and promoting new members. Leaders should expect to step aside. Members in the community should be prepared to step up.
Community comes first
We're here first and foremost as a community, and our devotion is to the Qbeast project's intentional care for the benefit of all its members and users globally. We believe in publicly cooperating toward the common objective of creating a dynamic, interoperable ecosystem ensuring our users have the best experience possible.
Individuals achieve status by their efforts, and businesses gain status via their commitments to support this community and fund the resources required to keep the project running.
Distributing is Caring
The scale of the Qbeast Spark project can only be achieved through highly reliable and highly visible assignments, including authorization, decision-making, technical design, code ownership, and documentation. Our global community is built on distributed asynchronous ownership, cooperation, communication, and decision-making.
As Pablo Picasso once said:
"Action is the foundational key to all success."